【MELSOFT MaiLab入門】3分でデータ分析・AI活用を体感|Fisher’s Iris Dataset

Fisher’s Iris Dataset―通称Irisデータセット。データサイエンスの世界では最も有名な、アヤメの花びらのクラス分類に関するデータセットです。本記事ではMELSOFT MaiLabを使用し、Fisher’s Iris Datasetの分析と判定に挑戦します。
皆様ぜひともMaiLabの応援をよろしくお願いします。

1. データ準備
データ準備の手順は【データセットのダウンロード】→【CSV化】→【学習データとテストデータに分割】という作業になります。
必要スキル:PowerQueryの基本操作、Pythonの基本操作
【初心者・お忙しい方向け】
分割済みCSVファイルを用意しました。(クリックして開く)
| 名称 | Fisher’s Iris Dataset |
|---|---|
| 出展 | R.A. Fisher, The use of multiple measurements in taxonomic problems, Annual Eugenics, 7, Part II, pp. 179-188, 1936. |
| URL | https://archive.ics.uci.edu/dataset/53/iris |
| ライセンス | Creative Commons Attribution 4.0 International (CC BY 4.0) |
| 本配布データの変更点 | bezdekIris.dataをExcelを介しclass毎にCSV形式に変換し、Pythonで学習データとテストデータに分割した。具体的な分割手法は、df=pandas.read_csvで読み込んだbezdekIris_[class].csvを、test_data=df.sample(frac=0.1, random_state=1)にて抽出。その後df.drop(test_data.index)にてbezdekIris_[class].csvからテストデータを除外することで学習データを作成した。 |
- 同内容は「MELSOFT MaiLab Irisデータ(分割済み)/README.txt」にも記載。
【玄人・時間のある方向け】
以下の手順でIrisデータセットを、学習用データと評価用データに分割してください。
ダウンロードしたzipファイルを解凍すると、以下の構成でデータが保存されているのが確認できます。本記事ではサイトのお知らせを参考にbezdekIris.dataを使います。
まず空のExcelブックを開きます。データリボンから[データの取得]の[変換のテキストまたはCSVから]をクリックします。
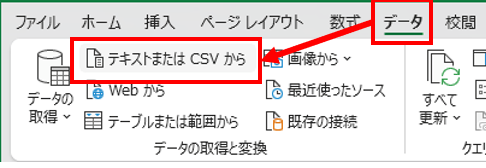
右下の[テキストファイル]を[すべてのファイルに変更し、bezdekIris.dataを選択、インポートします。
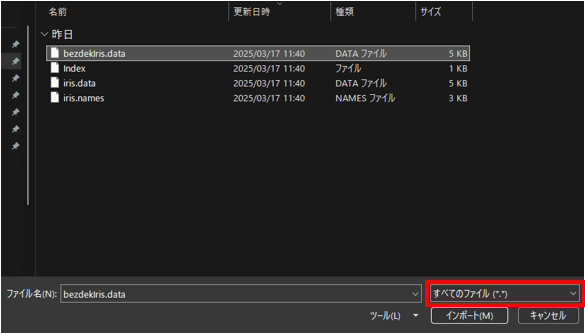
[データの変換]をクリックし、参照とclass列のフィルターを駆使して以下のように「bezdekIris_setosa」「bezdekIris_versicolor」「bezdekIris_virginica」の3クエリを作成します。
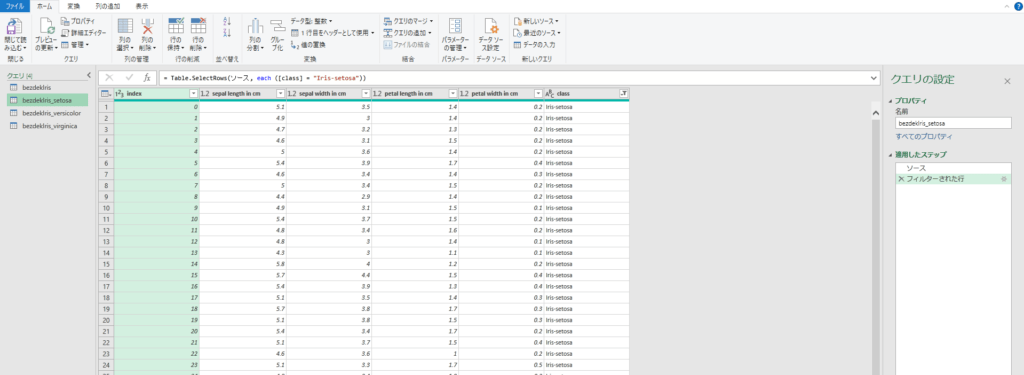
「bezdekIris_setosa」「bezdekIris_versicolor」「bezdekIris_virginica」タブをそれぞれ「ファイル」リボンを開く→「エクスポート」→「ファイルの種類の変更」→「別のファイル形式として保存」を選択し、CSV UTF-8(コンマ区切り)注意 形式で保存します。

簡単にExcelでここも済ませられればよかったですが、うまいことできなかったのでPythonでCSVを分割します。
任意のフォルダにて、先ほど出力したCSVと以下のmain.pyを同一フォルダに配置し、pandasが動作するpython環境にて実行してください。
本記事の環境:Python3.13.2
pandas:上記環境に標準装備されているバージョン
import pandas as pd
def main():
csv_list = ['bezdekIris_setosa', 'bezdekIris_versicolor', 'bezdekIris_virginica']
for name in csv_list:
# CSVファイルの読み込み
df = pd.read_csv(name+'.csv', index_col=0)
test_ratio = 0.1 # 分割する比率
# データをランダムにサンプリングして分割
test_data = df.sample(frac=test_ratio, random_state=1) # テストデータ
train_data = df.drop(test_data.index) # トレーニングデータ
test_data.to_csv(name+'_test_data.csv')
train_data.to_csv(name+'_train_data.csv')
print(f'「'+name+'」処理しました。')
if __name__ == "__main__":
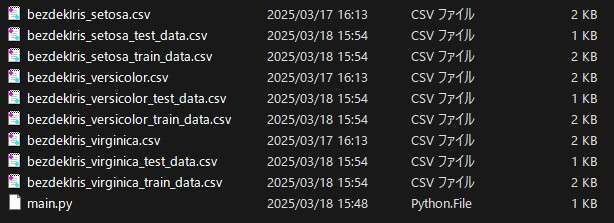
main()以下のようなファイルが出力されれば完了です。
2. MaiLabにデータを取り込む
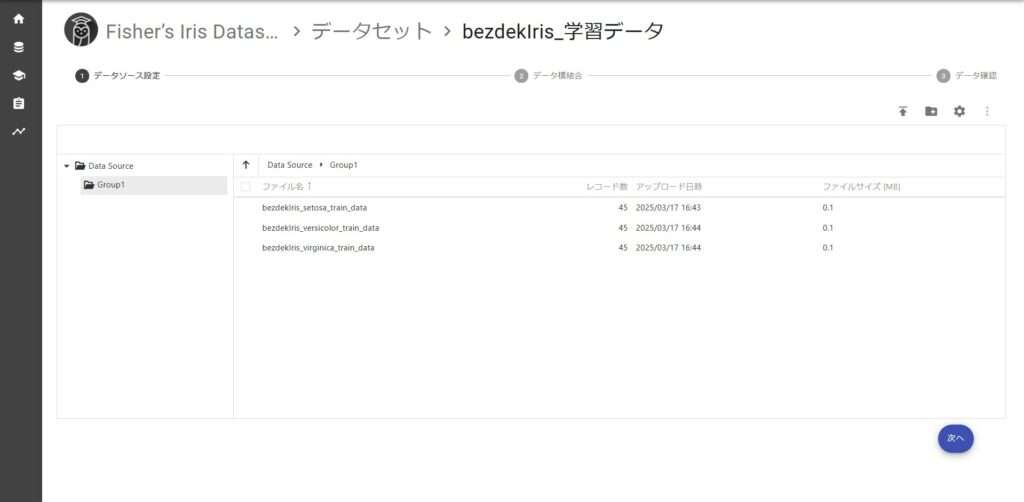
次にデータセットの追加を行います。学習データの作成方法を例に挙げますが、テストデータも同様に作成してください。
「***_train_data.csv」をすべてGroup1に追加します。
index列は「使用しない」を選択してください。
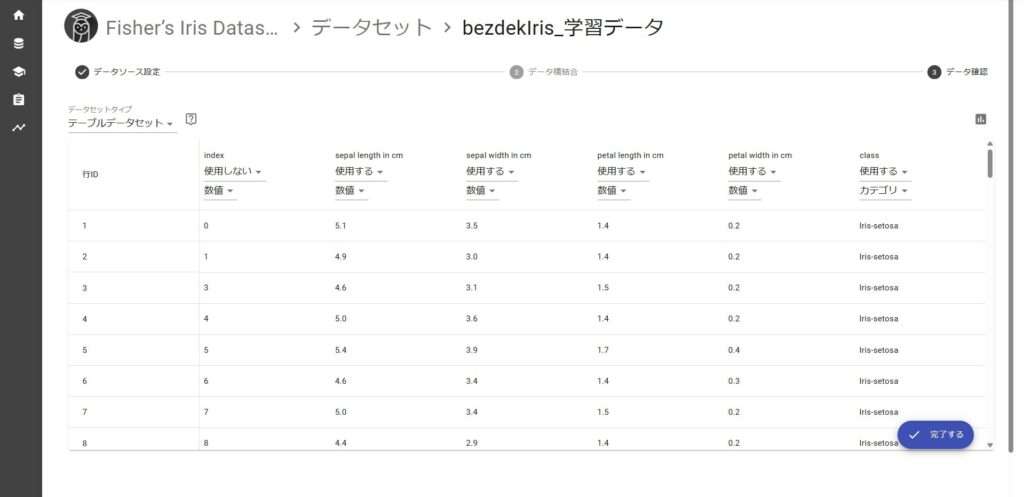
「***_test_data.csv」をStep1とStep2の操作で、同様に作成します。
以下のようになればOKです。
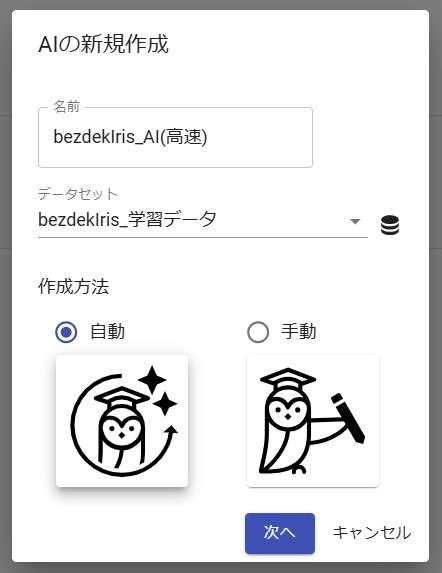
3. AIを作成
次にAIを作成します。AIを新規作成し、任意で名前を入力します。データセットは先ほど作成した学習データを選択します。AIの作成方法は自動を選択します。
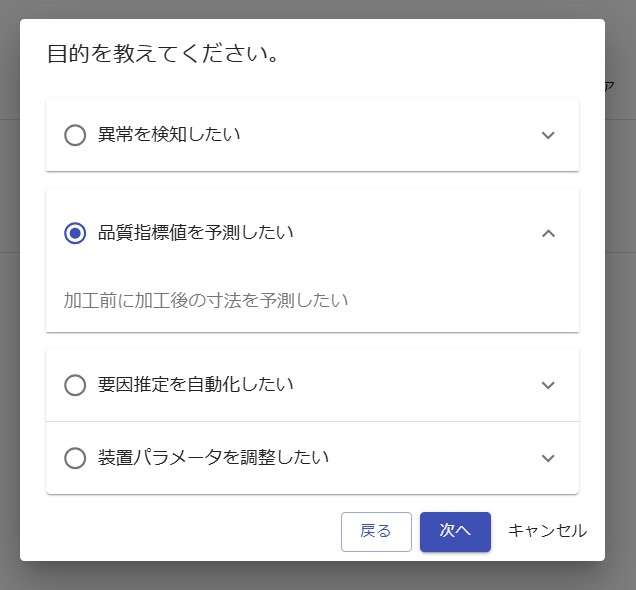
目的を品質指標値を予測したいにし、予測したい変数をclassとします。
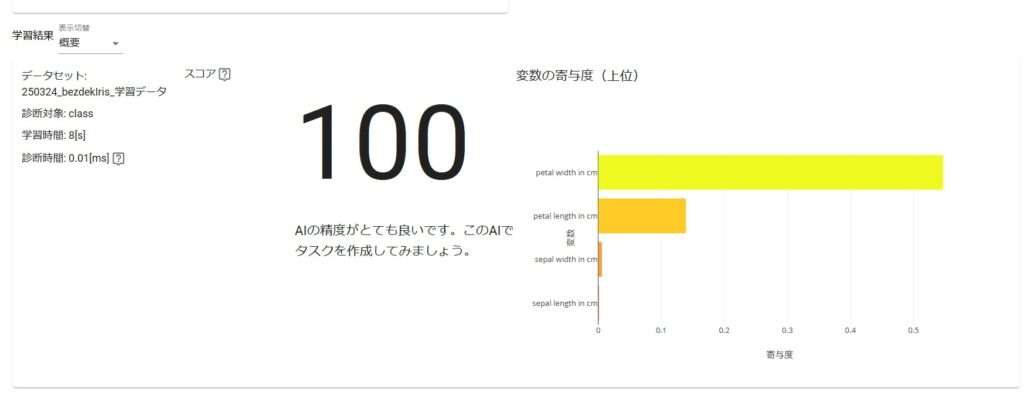
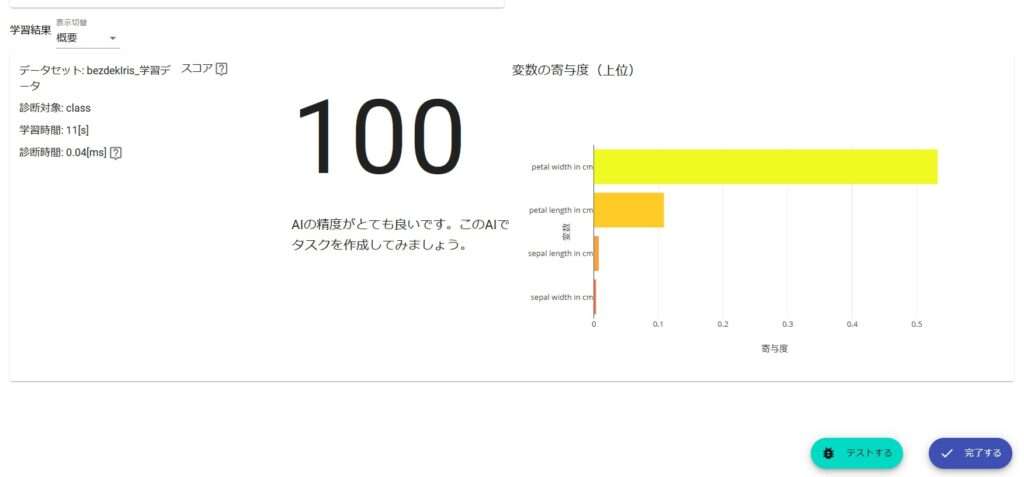
学習を開始します。今回作成したAIはスコア100になりました(びっくり)
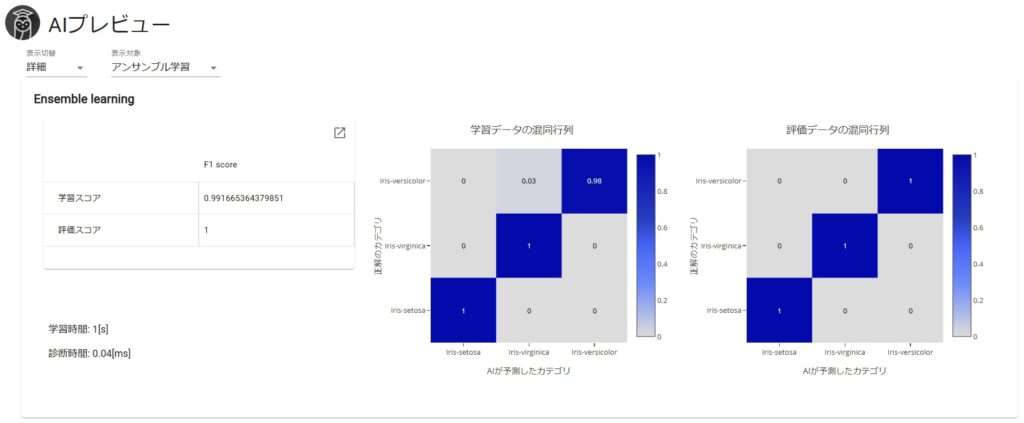
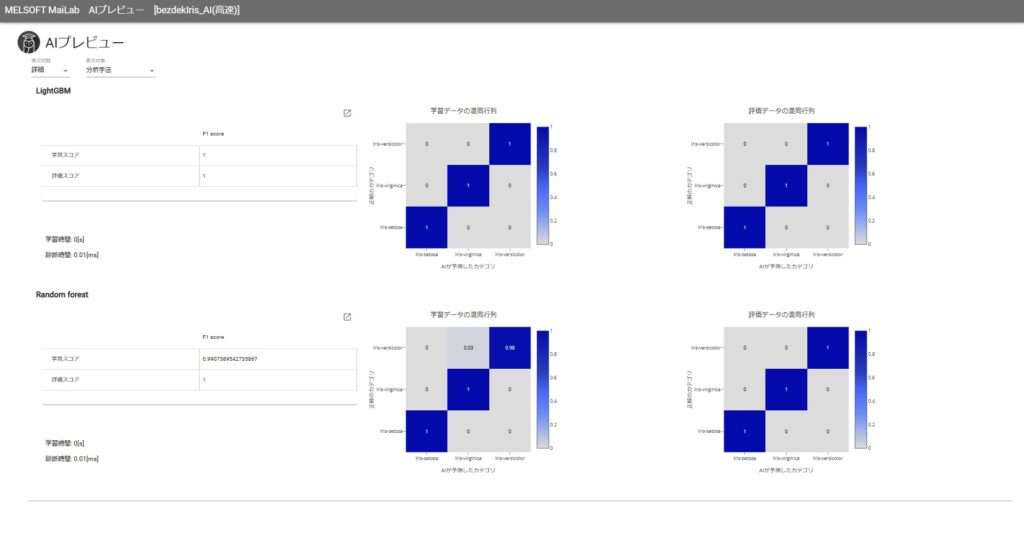
おまけ:手法別の精度
アンサンブル学習だったのでLightGBMとRandomForestからの総合的な判定にはなりますが、各結果は以下のようになりました。
4. AIをテスト
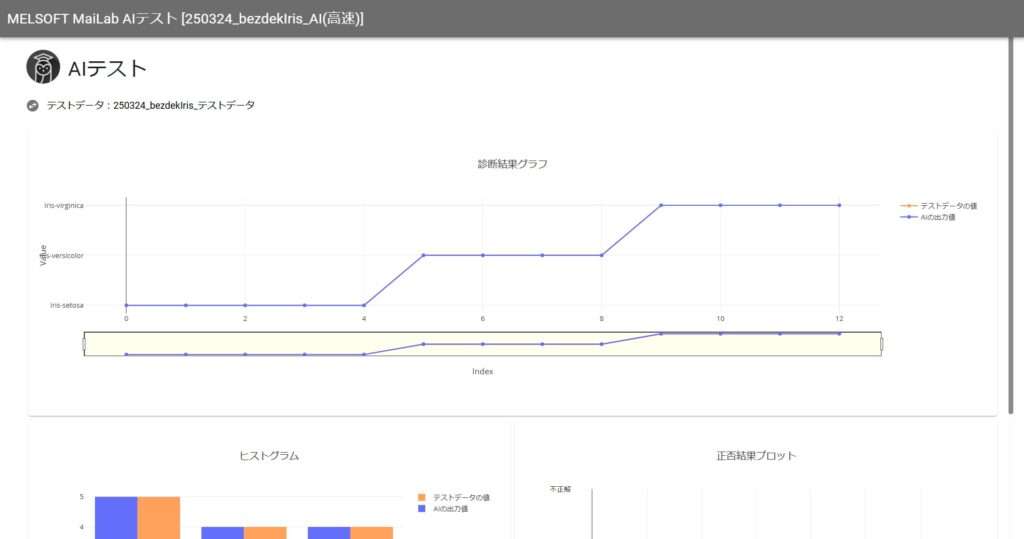
作成したAIの名前を右クリックし「テスト」を選択します。比較データセットはテストデータを選択します。学習スコアが100ではありましたが、テストの結果は15データ中2つの判定ミスがありました。
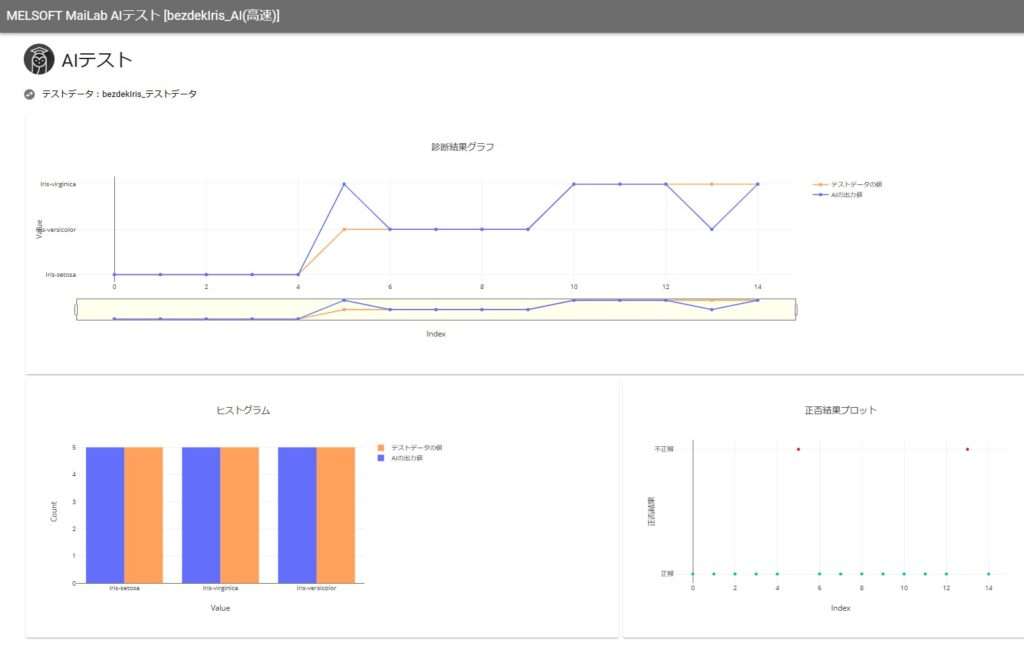

モデル作成時はスコア100だったのにテストで間違えることがあるんですね……モデルは完璧なはずでは?

AIの学習データ内に、様々な状況を網羅したデータが入ってなかったみたいですね!間違えた検証データを含めて再度学習させると、より判定を間違えにくいAIが作成できますよ。
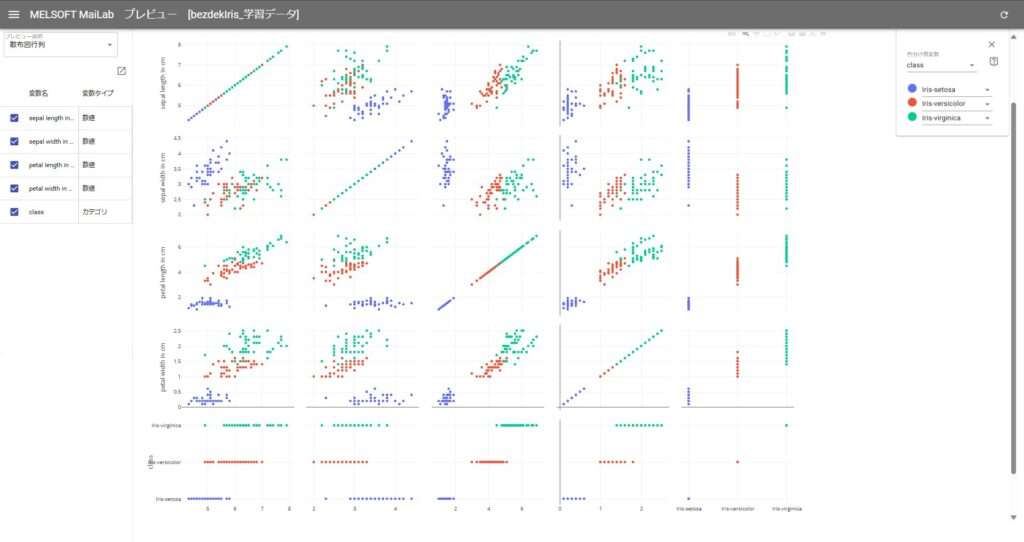
おまけ:データの分布
判定ミスをしたクラスは「versicolor(下図赤点)」と「virginica(下図緑点)」ですが、データセットの分布をみると「setosa(下図青点)」と比較して分布に重なりがあるので、判定が難しかった可能性があります。
おわりに
データサイエンスの世界ではもっとも有名なデータセット:Fisher’s Iris Datasetを、MELSOFT MaiLabのみ(※データセット作成は除く)で分析・判定してみました。データがあれば数分でここまでできるのはラクですね。
おまけ:判定ミスをした要素を加えて学習する
上記No.5とNo.13のデータを学習用のデータに加え(テストデータからは削除)、再度AIモデルを作成しました。結果としては、スコアは同じく100、判定結果はミスなしとなりました。